Snap ML Accelerates Machine Learning
Article By : Gary Hilson

IBM sees 46x speed-up in machine learning with new tech
TORONTO — IBM wants to make machine learning as fast as snapping your fingers. At its own IBM THINK conference this week, IBM Research unveiled a newly published benchmark using an online advertising dataset released by Criteo Labs of more than 4 billion training examples. IBM was able to train a logistic regression classifier in 91.5 seconds — 46 times faster than the best result that has been previously reported, which used TensorFlow on Google Cloud Platform to train the same model in 70 minutes.
In a telephone briefing with EE Times, IBM Research’s manager for non-volatile memory, Haris Pozidis, said the results outlined in the recent paper are a culmination of nearly two years woth of work. “When we started off, it was to make machine learning accessible to people and also make machine learning much faster than what it was and what it is today,” Pozidis said.
Known as IBM Snap Machine Learning (Snap ML) because it trains models “faster than you can snap your fingers,” the new library powered by artificial intelligence software provides high-speed training of popular machine learning models on modern CPU/GPU computing systems and can be used to train models to find new and interesting patterns, or to retrain existing models at wire-speed as new data becomes available. The resulting benefits include lower cloud costs for users, less energy, more agile development and a faster time to result.
There are three core elements that distinguish IBM’s Snap ML. The first is distributed training. The system is built as a data-parallel framework that supports the ability to scale out and train on massive datasets that exceed the memory capacity of a single machine, which is crucial for large-scale applications.
The second element is GPU acceleration. IBM used specialized solvers designed to leverage the massively parallel architecture of GPUs while respecting the data locality in GPU memory to avoid large data transfer overheads. It also takes advantage of recent developments in heterogeneous learning to make it scalable. Finally, recognizing that man machine learning datasets are sparse, new optimizations for the algorithms were used in IBM’s system.
“Most machines might have a heterogeneous compute infrastructure,” said Thomas Parnell, an IBM Research mathematician. “But the way we distribute the training, we do in a way to try to minimize the amount of communication that had to be made between the different modes between the training. This allows us to avoid the overhead of communicating large amounts of data over the network.”
Parnell said the effective support for sparse data structures is quite novel, and is further outlined in the research paper, as are some comparisons with the existing libraries for performing these kinds of tasks.
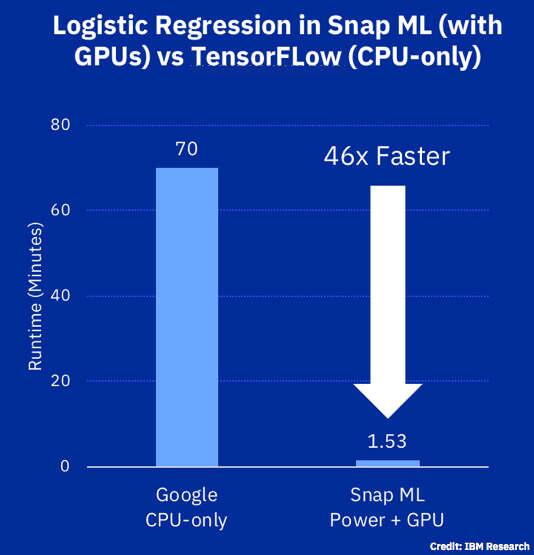
IBM Research used an online advertising dataset released with more than four billion training examples to a logistic regression classifier in 91.5 seconds.
In particular, IBM looked at Google’s TensorFlow framework, which primarily focuses on machine learning on large scale linear models. “TensorFlow is quite flexible,” said Parnell. “It can support GPU acceleration. It can also scale out from multiple nodes. One of the downsides that we found working with TensorFlow is it has relatively limited support for sparse data structures.”
Another finding of the IBM researchers was that when deploying GPU acceleration for such large-scale applications, the training data is too large to be stored inside the memory available on the GPUs. This means that during training, data needs to be processed selectively and repeatedly moved in and out of the GPU memory. To profile the runtime of their application, the researchers analyzed how much time is spent in the GPU kernel compared with how much time is spent copying data on the GPU.
In the paper, the researchers also explored different levels of parallelism, said Celestine Duenner, a pre-doctorate researcher at IBM Research. “The first level is distributing the workload across different nodes in a cluster. The second level is to distribute the workload among the different compute units within a node and the third level is to use all the quarries and all the parallelism offered by this individual compute unit,” Duenner said.
She said the first level in the cluster is where communication is most expansive because it must go over the network, but enables training on large data sets that don’t fit inside the memory of a single machine. “We use distributed training so that we can use the aggregated memory of multiple machines,” she said. “We use state-of-the-art techniques to organize the work between the nodes, which is communication efficient.”
Ultimately, said Parnell, the goal was to speed up machine learning and make it accessible with computing infrastructure commercially available today. “The training time can be really critical, especially if you’re buying cloud resources with GPUs for instance,” he said. “Cloud instances are normally billed by the hour, so the longer you use them, the more you pay for them.”
Customers will able take advantage of the work done by IBM Research as part of the PowerAI Tech Preview portfolio later this year, and IBM is currently looking for clients interested in pilot projects.
—Gary Hilson is a general contributing editor with a focus on memory and flash technologies for EE Times.

Subscribe to Newsletter

Test Qr code text s ss
