Who’s Winning the AI Inference Race?
Article By : Sally Ward-Foxton

MLPerf has released the first set of benchmark scores for its inference benchmark, following scores from the training benchmark which were released earlier this year.
MLPerf has released the first set of benchmark scores for its inference benchmark, following scores from the training benchmark which were released earlier this year.
Compared to the training round, which currently has 63 entries from 5 companies, many more companies submitted results. In total there were more than 500 scores verified from 14 organisations. This included figures from several startups, while some high-profile startups were still noticeably absent.
In the closed division, whose strict conditions enable direct comparison of the systems, the results show a 5-order of magnitude difference in performance, and span three orders of magnitude in terms of estimated power consumption. In the open division, submissions can use a range of models, including low precision implementations.
Nvidia claimed the number one position for commercially available devices across all the categories in the closed division. Other leaders included Habana Labs, Google and Intel in the datacentre categories, while Nvidia competed with Intel and Qualcomm in the edge categories.

Nvidia’s EGX platform for data centre inference (Image: Nvidia)
“Nvidia is the only company that has the production silicon, software, programmability, and talent to publish benchmarks across the spectrum of MLPerf, and win in almost every category,” said Karl Freund, Analyst, Moor Insights and Strategy. “The programmability of GPUs uniquely positions them well for future MLPerf releases… I think this demonstrates the breadth of [Nvidia’s] strength, and also the niche nature of the challengers. But many of those challengers will mature over time, and so Nvidia will need to continue to innovate in both hardware and software.”
Nvidia published graphs showing its interpretation of the results, placing itself in the number one position across all four scenarios in the closed division for commercially available devices.
These scenarios represent different use cases. The offline and server scenarios are for inference in the data centre. The offline scenario might represent offline photo-tagging for a large number of pictures and measures pure throughput. The server scenario represents a use case with multiple requests from different users, submitting the requests at unpredictable times, and it measures throughput in a fixed time. The edge scenarios are single stream, which times inference for a single image such as in a mobile phone app, and multi-stream, which measures how many streams of images can be inferenced simultaneously, for multi-camera systems.
Companies can submit results for selected machine learning models performing image classification, object detection and language translation in each of the four scenarios.
Data center results
“Looking at the data center results, Nvidia topped on all five benchmarks for both the server and the offline categories,” said Paresh Kharya, Director of Product Management for Accelerated Computing, Nvidia. “Our Turing GPUs outperformed everyone else amongst the commercially available solutions.”
Kharya highlighted the fact that Nvidia was the only company to submit results across all five of the benchmark models for the data centre categories, and that for the server category (which is the more difficult scenario), Nvidia’s performance increased relative to its competitors.
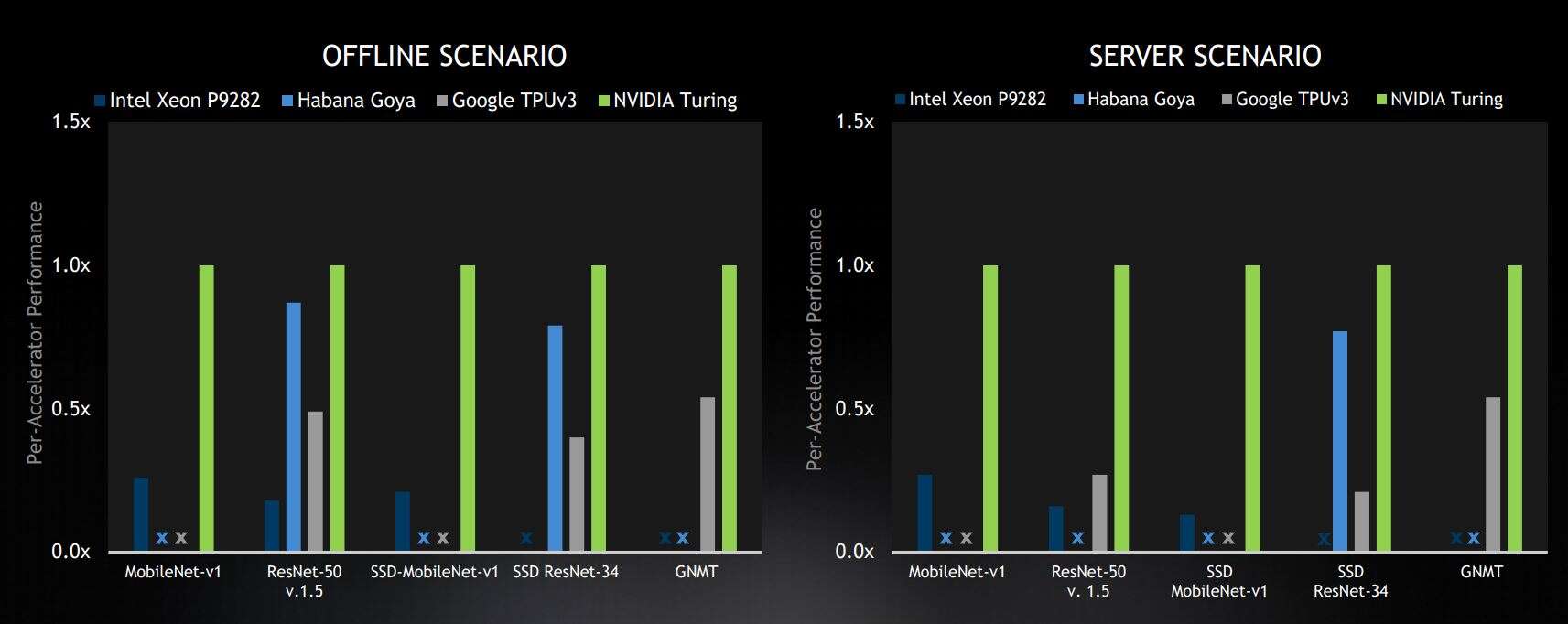
Selected data centre benchmark results from closed division, leaders in the commercially available device category. Results are shown relative to Nvidia scores on a per-accelerator basis. X represents “no result submitted” (Image: Nvidia)
Nvidia’s closest competitor in the data centre sector is Israeli startup Habana Labs with its Goya inference chip.
“Habana stands as the only challenger with high performance silicon in full production, and should do well when the next MLPerf suite hopefully includes power consumption data,” said analyst Karl Freund.
In an interview with EETimes, Habana Labs pointed out that the benchmark scores are purely based on performance – power consumption is not a metric, nor is practicality (such as considering whether a solution is passively cooled or water cooled), nor is cost.

Habana Labs PCIe card featuring its Goya inference chip (Image: Habana Labs)
Habana also used the open division to show off its capability for low latency, restricting the latency further than for the closed division, and submitting results for the multi-stream scenario.
Edge Compute Results
For the edge benchmarks, Nvidia won all four of the categories that had submitters in the closed division for commercially available solutions. Qualcomm’s Snapdragon 855 SoC and Intel’s Xeon CPUs trailed Nvidia in the single-stream category, and neither Qualcomm or Intel submitted results for the more difficult multi-stream scenario.
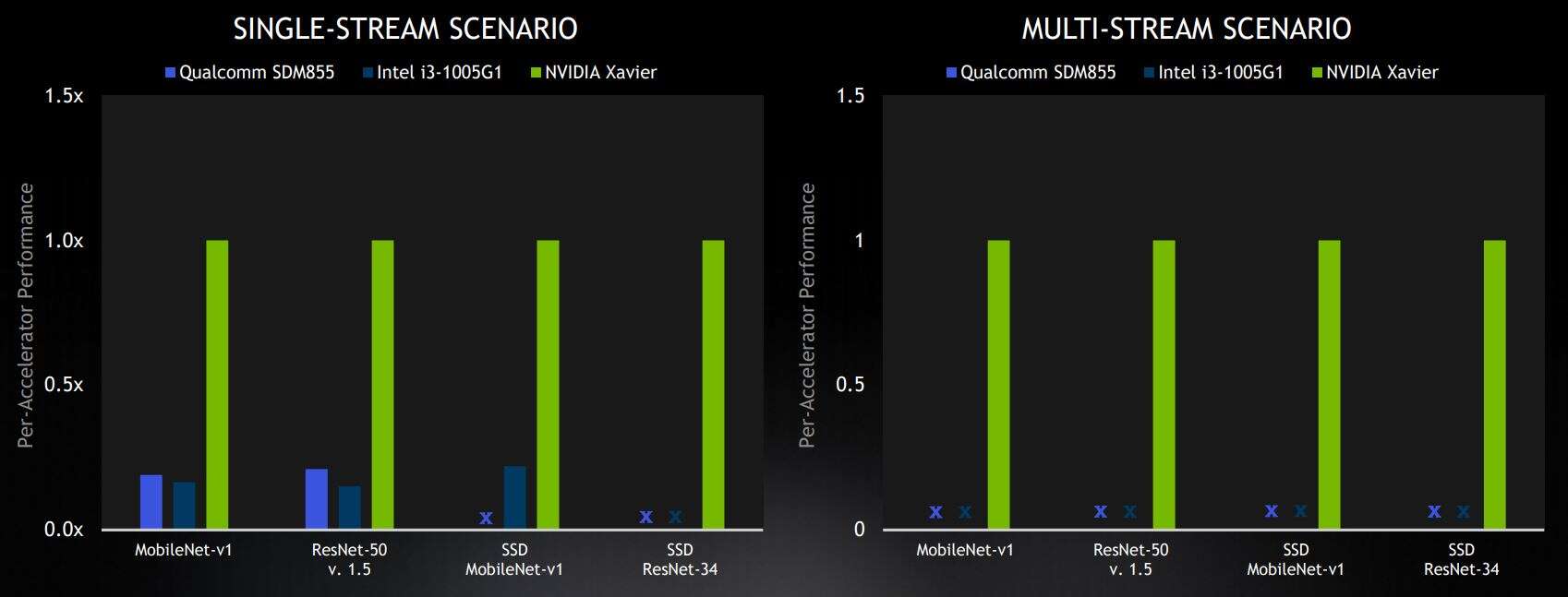
Selected edge benchmark results from closed division, leaders in the commercially available device category. Results are shown relative to Nvidia scores on a per-accelerator basis. X represents “no result submitted” (Image: Nvidia)
Results for “preview” systems (those that are not yet commercially available) pitted Alibaba T-Head’s Hanguang chip against Intel’s Nervana NNP-I, the Hailo-8, and a reference design from Centaur Technologies. Meanwhile the R&D category featured a stealthy Korean startup, Furiosa AI, about which very little is known.
The full spreadsheet of MLPerf Inference scores may be viewed here.

Subscribe to Newsletter

Test Qr code text s ss
