Latest AI Algorithms Presented at NeurIPS
Article By : Sally Ward-Foxton

Advances will help machines identify objects and figure out how to work together, improve their ability to understand language, and improve their ability to learn.
A human can look at a bird and understand its shape in 3-D space. What is simple intuition for humans is an extraordinary task for a machine, but AI researchers keep devising innovative new ways for machines to do things humans do naturally. Several intriguing advances were revealed at NeurIPS, the annual mass convergence of AI researchers, held last week in Vancouver, Canada.
Here are the details on a selection of interesting papers from the hundreds presented, in no particular order.
Nvidia: 3D from 2D
Nvidia presented an inverse rendering framework which predicts 3D information about objects based on 2D photographs and videos.
EETimes spoke to the paper’s co-author, Professor Sanja Fidler, director of AI at Nvidia (she is also a professor at the University of Toronto).
“3D is super important for robotics, to grasp objects and navigate through scenes,” she said. “For that you need to have some understanding of the world, how the geometry of the world actually looks.”
This is a hot research topic today. The main issue, Fidler said, is that while imagery created for use in robotics often has 3D information associated with it, perhaps from complementary sensors, most of the imagery available today from other sources does not have this 3D information available. Nvidia is working towards a way to infer 3D data from this imagery so it can be used for robotics purposes.
Fidler’s team have built an inverse renderer that, crucially for machine learning, produces differentiable results. Rendering, a well-known process in the world of computer graphics, produces 2D projections of objects and scenes from 3D data. The aim here is to do the inverse: go from 2D to 3D.

Results from Nvidia’s algorithm which created 3D objects from single pictures of birds (Image: Nvidia)
Nvidia’s algorithm, called DIB-R (differentiable interpolation-based renderer), is “the most complete so far,” Fidler said. It can predict geometry, colours and textures of objects, and infer lighting in the scene.
“It can do this very efficiently because all the parameters are computed analytically, which is very important for machine learning,” said Fidler. “Older techniques which already exist in this domain relied on hand-designed gradients and approximate gradients, and were much harder to train.”
It takes two days to train Nvidia’s model on a single V100 GPU, and inference takes less than 100 milliseconds. 3D objects are created by successively altering a polygon sphere.
“I think the cool part here is that all these fields are coming together through deep learning. Before you had computer vision, graphics, natural language processing, everything was segregated, the communities were different,” said Fidler. “But deep learning is enabling all these communities to connect and all this knowledge from different fields to benefit each other because there are really tight connections between the communities or domains, and we are now able to combine them and make more powerful machine learning models.”
DIB-R will be available to developers through Nvidia’s Kaolin library.
Intel: teaching robots teamwork
Researchers from Intel, Oregon State University, and University of California at Irvine, presented a paper about a new type of reinforcement learning that can teach groups of robots to co-operate.
In reinforcement learning, two AI agents (algorithms that performs some action) work together to improve their combined result. One agent produces results while the other evaluates those results, rewarding results that closely resemble the intended outcome with a higher score.
The new technique, MERL (multi-agent evolutionary reinforcement learning), builds on Intel’s existing work on CERL (collaborative evolutionary reinforcement learning), which allowed agents to learn challenging continuous control problems, such as training a humanoid robot to walk from scratch.
MERL can train teams of robots to jointly solve tasks. This is a tricky problem since the goals of individual agents may differ from the team’s overall target. Individual goals are also usually denser, meaning they are quicker and easier to achieve and thus more attractive. Training the agents to work towards both sets of results at the same time is particularly difficult.
The team is also working on similar problems involving multi-task learning in scenarios that have no well-defined reward feedback, and the role of communication in these tasks.
IBM: training with 8-bit data
One of the papers presented by IBM considered techniques for low-precision training. While low-precision data is often used for inference, higher precision numbers are used in training systems to preserve the accuracy of the weights in the resulting model. However, switching to lower precision numbers (a process known as quantisation) is attractive because less compute, less storage and less power are needed.
IBM presented the first 8-bit training techniques at NeurIPS last year, including an 8-bit floating point scheme. This year, it presented a hybrid approach (hybrid 8-bit floating point, or HFP8) which aims to improve compute performance while maintaining accuracy for the most challenging state-of-the-art deep neural networks.
This work improves on last year’s developments as the new format, HFP8, overcomes previous training accuracy loss on models susceptible to information loss from quantisation. HFP8 uses a novel FP8-bit format in the forward path for higher resolution and another FP8-bit format for gradients in the backward path for larger range.
Google: training giant networks
As the size of deep neural networks (DNNs) continues to increase, they are pushing the limits of memory in processing chips, even those specially designed for the purpose like Google’s own TPU (tensor processing unit). Multiple accelerators can be used, but DNNs’ sequential nature means that if done improperly, only one accelerator is active at any one time, which is inefficient. Data parallelism may be used, where the same model is trained with different subsets of data on each chip, but this doesn’t scale to larger models.
A team at Google has use pipeline parallelism to try to overcome this problem. They created GPipe, a new machine learning library which works on any neural network that can be expressed as a sequence of layers. The new library allows researchers to easily deploy more accelerators to train larger models and to scale the performance without tuning hyperparameters.
GPipe partitions the model to be trained across multiple accelerators, splitting the batches of data into smaller micro-batches using a novel batch-splitting pipelining algorithm. This can result in almost linear speedup when model training is partitioned across multiple accelerators, the researchers said.
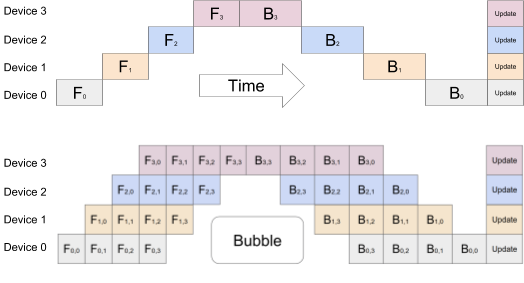
Top: Older model parallelism strategies lead to underutilization due to the sequential nature of DNNs. Only one accelerator is active at a time. Bottom: GPipe divides the input mini-batch into smaller micro-batches, enabling different accelerators to work on separate micro-batches at the same time (Image: Google)
Facebook: SuperGLUE
A research team from Facebook, New York University, University of Washington, and DeepMind has been working on a new benchmark for algorithms that understand language. Originally called GLUE, the benchmark offers a single-number metric for model performance based on a set of nine natural language processing (NLP) tasks.
In the last year, algorithms for understanding language have come on leaps and bounds, surpassing the performance of non-expert humans in some cases. GLUE therefore needed to evolve. The team has updated their work into a new benchmark that includes more rigorous NLP tasks, a software toolkit and a public leaderboard. And they’ve renamed it SuperGLUE.
Per the latest benchmark scores, Google is currently in the lead with its T5 model which got a score of 88.9 (close to the human baseline which scored 89.8). Facebook’s RoBERTa model clocks in at 84.6 with IBM’s BERT-mtl at 73.5.
SuperGLUE is available at super.gluebenchmark.com.

Subscribe to Newsletter

Test Qr code text s ss
