Labeled or Unlabeled Data, Does it Make a Difference?
Article By : Junko Yoshida
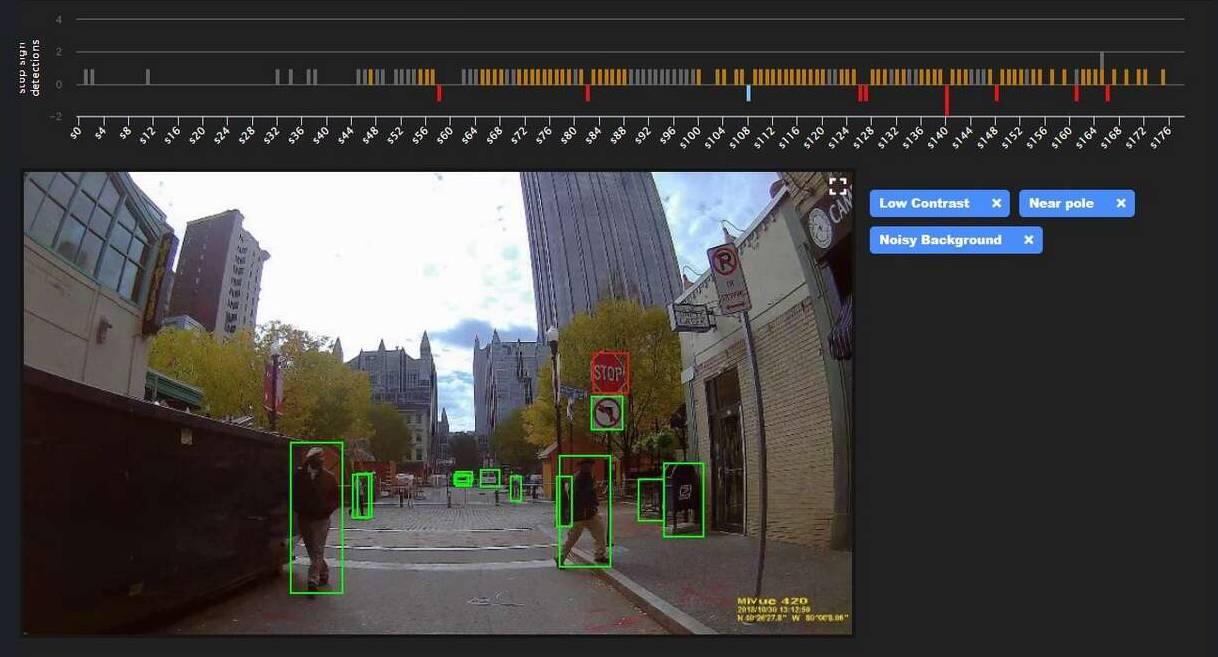
Assume that AV companies have already collected petabytes, or even exabytes of data on real roads. How much of that dataset has been labeled? How accurate is it?
Data is everything — in many respects, it’s the only thing — for autonomous vehicles (AVs) vendors who depend on deep learning as the key to self-driving.
Data is the reason AV companies are racking up miles and miles of testing experience on public roads, recording and stockpiling petabytes of road lore. Waymo, for example, claimed in July more than 10 million miles in the real world and 10 billion miles in simulation.
But here’s yet another question the industry does not like to ask:
Assume that AV companies have already collected petabytes or even exabytes of data on real roads. How much of that dataset has been labeled? Perhaps more important, how accurate is the data that’s been annotated?

In a recent interview with EE Times, Phil Koopman, co-founder and CTO of Edge Case Research, asserted that “nobody can afford to label all of it.”
Data labeling: time-consuming and costly
Annotation typically requires expert human eyes to watch a short video clip, then draw and label boxes around every car, pedestrian, road sign, traffic light, or any other item possibly relevant to an autonomous driving algorithm. The process is not just time-consuming but very costly.
A recent story on Medium entitled “Data Annotation: The Billion Dollar Business Behind AI Breakthroughs” illustrates the rapid emergence of “managed data labeling services” designed to deliver domain-specific labeled data with an emphasis on quality control. The story noted:
In addition to their in-house data labeling crews, tech companies and self-driving startups also rely heavily on these managed labeling services…some self-driving companies are paying data labeling companies upwards of millions of dollars per month.
In another story from IEEE Spectrum a few years ago, Carol Reiley, cofounder and president at Drive.ai was quoted saying:
Thousands of people labeling boxes around things. For every one hour driven, it’s approximately 800 human hours to label. These teams will all struggle. We’re already magnitudes faster, and we’re constantly optimizing.
Some companies, such as Drive, are using deep learning to enhance automation for annotating data, as a way to accelerate the tedious process of data labelling.
Let’s use unlabeled data
Koopman, however, believes there is another way to “squeeze the value out of the accumulated data.” How about accomplishing this “without labeling most of the petabytes of recorded data?”
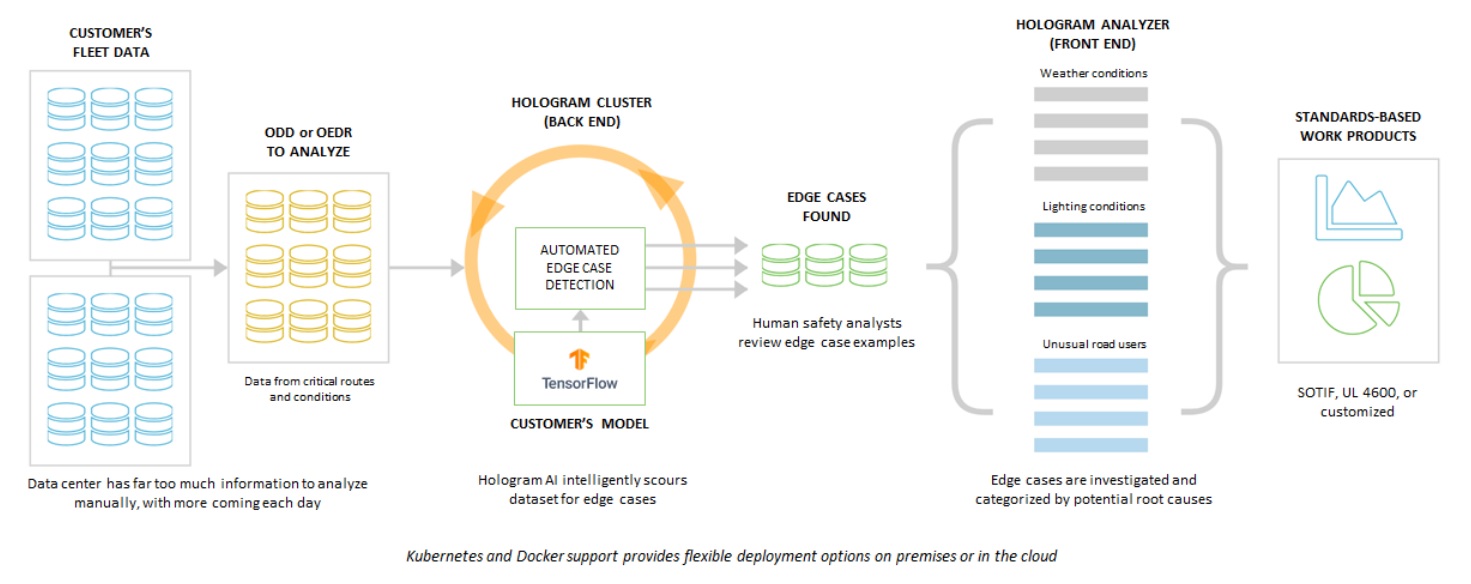
He explained that Edge Case Research “stumbled into” this, when devising a way to allow the AV industry to speed development of safer perception software. Edge Case Research calls it “Hologram,” which is in essence an “AI perception stress testing and risk analysis system” designed for AVs.
More specifically, as Koopman explained, “Hologram uses unlabeled data,” and the system runs the same unlabeled data twice.
First, it runs baseline unlabeled data on an off-the-shelf, normal perception engine. Then, with the same unlabeled data, Hologram is applied, adding a very slight perturbation — noise. By putting stress on the system, Hologram, as it turns out, can expose potential weakness of the perception in AI algorithms.
If a little grain is added to a video clip, for example, a human might perceive that “there is something there, but I don’t know what it is.”
But an AI-driven perception system, put under stress, can either totally miss an unknown object, or kick it across the threshold and put it into a different classification bin.
When AI is still learning, knowing its confidence level (as it determines what it is seeing) is useful. But when AI is applied in the world, confidence level doesn’t tell us much. AI is often “guessing” or simply “assuming.”
In other words, AI is faking it.
Hologram, by design, can “poke” the AI-driven perception software. It exposes where an AI system failed. For example, a stressed system solves its confusion by mysteriously making an object disappear from the scene.
Perhaps, more interestingly, Hologram can also identify, under noise, where AI “almost failed” but guessed right. Hologram discloses areas in a video clip where the AI-driven system otherwise “could have gone unlucky,” said Koopman.
Without labeling petabytes of data but running it twice, Hologram can provide a heads-up where things look “fishy,” and areas where “you’d better go back and look again” by either collecting more data or doing more training, said Koopman.
This, of course, is a very simplified version of Hologram, because the tool itself, in reality, “comes with a lot of secret sauces backed by a ton of engineering,” Koopman said. But if Hologram can tell users “just the good parts” that merit human review, it can result in a very efficient way to get real value out of currently locked-up data.
“Machines are amazingly good at gaming the system,” noted Koopman. Or “doing things like ‘p-hacking.’” P-hacking is a type of bias that occurs when researchers collect or select data or statistical analyses until non-significant results become significant. Machines, for example, can find correlations within data where none exist.
Open source data set
Asked if this is good news for Edge Case Research, Koopman said, “Unfortunately, these data sets are made available only for the research community. Not for the commercial use.”
Further, even if you use such a data set to run Hologram, you should use the same perception engine used to collect data, to understand areas of weakness in one’s AI system.
Hologram’s screen shot
Below is a screen shot showing how the latest commercial version of Hologram works.
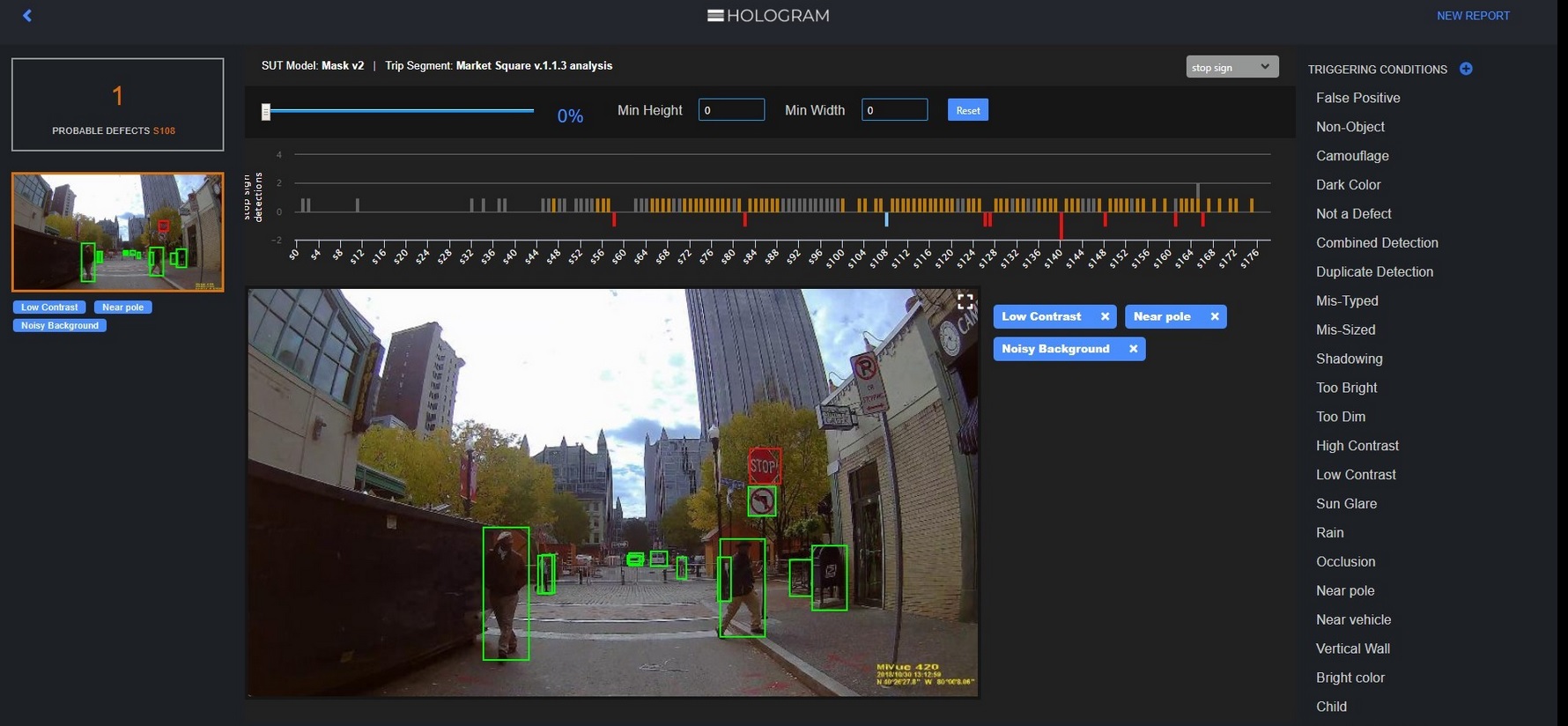
By adding noise, Hologram looks for triggering conditions that made an AI system almost miss a stop sign (orange bars), or completely failed to recognize a stop sign (downward red bars).
Orange bars warn AI designers about specific areas that require AL algorithm retraining, by collecting more data. Red bars allow AI designers to explore and speculate triggering conditions: What caused AI to miss the stop sign? Was the sign too close to a pole? Was there a noisy background or not enough visible contrast? When enough examples of triggering conditions accumulate, it might be possible to identify specific triggers, explained Eben Myers, product manager of Edge Case Research.
Partnership with Ansys
Earlier this week, Ansys announced a partnership agreement with Edge Case Research. Ansys plans to integrate Hologram into its simulation software. Ansys sees the integration as a critical underlying component to design “the industry’s first holistic simulation tool chain for developing AVs.” Ansys is collaborating with BMW, which has promised to deliver its first AV in 2021.


Subscribe to Newsletter

Test Qr code text s ss
