Implementing Machine Learning in Ultra-Low Power Systems
Article By : Sally Ward-Foxton

TinyML group debates using microcontrollers and specialist devices for ultra-low power machine learning.
When the TinyML group recently convened its inaugural meeting, members had to tackle a number of fundamental questions, starting with: What is TinyML?
TinyML is a community of engineers focused on how best to implement machine learning (ML) in ultra-low power systems. The first of their monthly meetings was dedicated to defining the issue. Is machine learning achievable for low power devices such as microcontrollers? And are specialist ultra-low-power machine learning processors required?
Evgeni Gousev from Qualcomm AI Research defined TinyML as machine learning (ML) approaches that consume 1mW or below. Gousev said that 1mW is the “magic number” for always-on applications in smartphones.
“There is a lot of talk about cloud ML, while ML at the smartphone level becomes more and more sophisticated,” he said. “But if you look at the data, 90 percent of the data is in the real world. How do you connect all these cameras, IMUs, and other sensors and do ML at that level?”
“Tiny ML is going to be big, and there is a real, urgent need to drive the whole ecosystem of tiny ML, including applications, software, tools, algorithms, hardware, ASICs, devices, fabs, and everything else,” Gousev said.

TensorFlow Lite
Google Engineer Daniel Situnayake presented an overview of TensorFlow Lite, a version of Google’s TensorFlow framework designed for edge devices including microcontrollers.
“TensorFlow Lite has been targeting mobile phones but we are excited about running it on ever smaller devices,” he said.
After building a model in TensorFlow, engineers can run it through the Tensor Flow Lite converter, which “makes it smaller and does things like quantisation, which allow you to reduce the size and precision of the model down to a scale where it will fit comfortably on the device you are targeting,” he said.
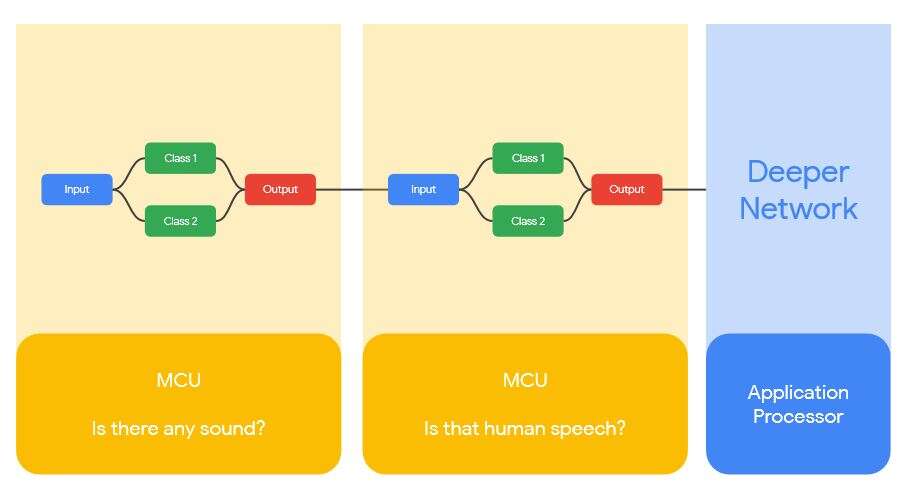
Situnayake described one technique that could be used to increase power efficiency, which involves chaining models together.
“Imagine a cascading model of classifiers where you have a really low power model using barely any power to detect if there is a sound going on, then another model that takes more energy to run, which figures out if it’s human speech or not,” he explained. “Then a deeper network that only wakes up when these conditions are met, that uses more power and resources. By chaining these together, you only wake up the [energy intensive] one when you need to, so you can make big savings on energy efficiency.”
Nat Jefferies, an engineer on Google’s ‘TensorFlow Lite for microcontrollers’ team, described the trend for strict energy consumption requirements in modern consumer gadgets, despite sophisticated features and sophisticated sensor systems. These gadgets may run on batteries that need to last months or years, or use energy harvesting.
“We think the best solution for this is Tiny ML — deep learning on microcontrollers,” he said. “This allows us to do CPU cycles and sensor reads, which [don’t take much power], as opposed to sending all the information off-chip… TinyML can be used to condense the sensor data into just a few bytes, which you can then send… for only a fraction of the power,” he said.
A recent Google challenge where entrants developed 250kbyte models to do person detection received many impressive submissions, and “validates that what we are doing is meaningful,” said Jefferies.
“Currently we are able to shrink TensorFlow models down to the point where we can fit them on microcontrollers, and that’s why now is an excellent time to be in this area,” he said. “We are excited to jumpstart this process.”
Google’s roadmap for TensorFlow Lite on microcontrollers includes open-sourcing some of Google’s demos, working with chip vendors to optimise kernels, optimising TensorFlow Lite’s memory usage to run more sophisticated models on the same devices, and enabling more development platforms (SparkFun Edge is the only board supported so far, but Arduino and Mbed board support is coming soon).
Specialist Devices
Presenting the case for specialist low power application processors for ML was Martin Croome, VP Business Development, GreenWaves Technologies. Croome agreed that industry discussion of how to proceed with ultra-low-power machine learning was overdue.
“We desperately need more focus in this area, both from the algorithmic perspective and from our [hardware] world as well,” he said.
GreenWaves has developed a RISC-V application processor, GAP8, which is focused on inference in edge devices that consumes milliWatts of power and offers ultra low standby currents. The company is targeting battery operated devices as well as devices that use energy harvesting (read more about how GreenWaves’ chip works in our earlier article).
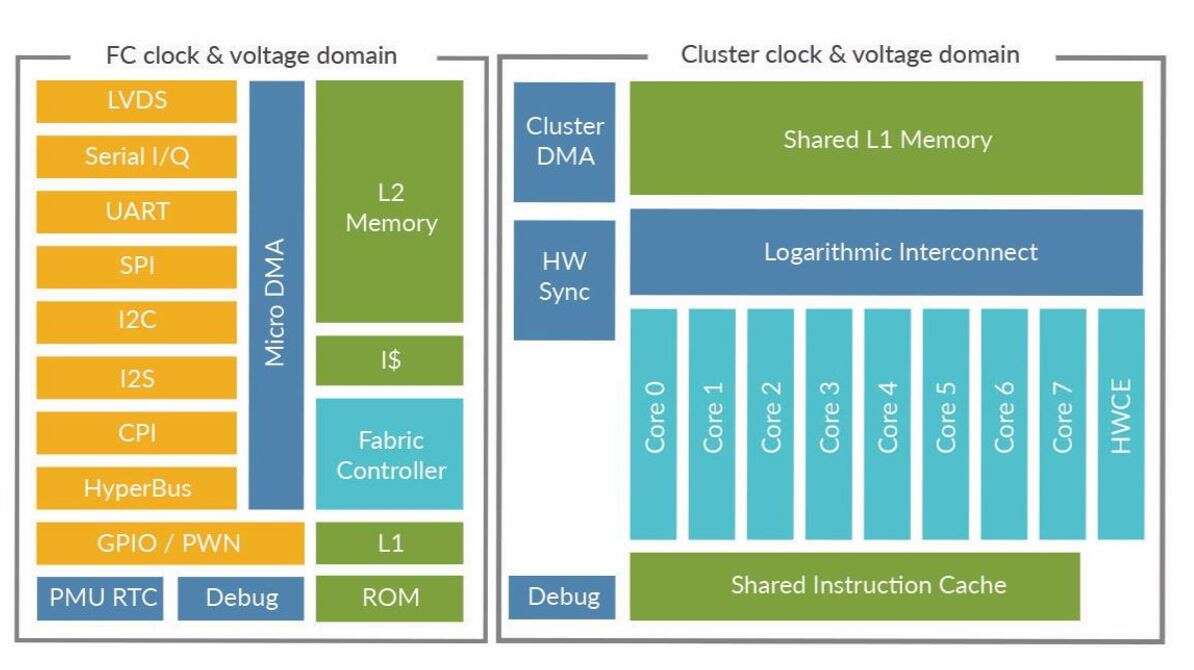
A variety of techniques are used to keep power consumption down. This includes parallelisation, though not to speed things up; 8 cores are used to allow a slower clock speed, which allows the core voltage to drop, which saves energy (in practice, the clock frequency is adjusted dynamically, depending on workload).
The chip is geared towards convolutional neural networks (CNNs), with a hardware accelerator performing a 5×5 convolution on 16-bit data in a single clock cycle (not including write back). Explicit memory management relies on the nature of CNNs, which are widely used for image processing; image sensors are a fixed size, inference requires the same number of weights, and the result is always the same size. A tool can therefore generate code for all the data movement at compile time.
Croome acknowledged that specialising enough to effectively process ML workloads while maintaining enough flexibility to respond to advances in technology is a tricky balance.
“The scope of AI is moving forward at a rate which is unbelievably fast. Today’s great idea about how to do things is probably not what tomorrow’s great idea is going to be,” said Croome. “If we specialise too much, we’ll be super great at accelerating what everyone was doing last year, which is not good for a company. So we are trying to balance the difference between flexibility, programmability and acceleration.”
GreenWaves’ chip has been sampling for a year, production will start this month, and it will be shipping in volume to customers by the end of Q3, Croome said.
TinyML meetups are held on the last Thursday of every month in the Bay Area and are open to attendees from both industry and academia.

Subscribe to Newsletter

Test Qr code text s ss
