HBM2e Top Contender for AI Applications
Article By : Sanjay Charagulla

HBM2e and GDDR6 DRAMs are vying for AI applications. However, HBM2e has a competitive edge. But you be the judge
Do you know which memory is best for your AI applications? These days, among artificial intelligence (AI) system designers, that’s not the most frequently asked question. Instead, the most asked question deals with AI accelerators.
Which one is best for my particular AI application? Is it capable of learning new things? What levels of complex calculations can it handle? And so on, and so forth.
But you, as a system designer, entering into this new AI frontier, do you know which memory is well suited as a companion for your selected AI accelerator?
One has to keep in mind that an AI memory gap exists to some degree. That’s because today’s and next generation AI accelerators are so fast that traditional memory technology lags behind as far as AI applications are concerned.
The AI accelerators and memory issues include high bandwidth, access time, and memory energy consumption on AI processor chips. In training or inference AI applications, convolutional neural networks (CNNs) or deep neural networks (DNNs) have a processing engine connecting to memory.
When data comes to the deep neural network (DNN) engine, a read is fetched from memory; the DNN engine computes the information, and then it writes it back to memory. Memory is stored with key weights, coefficients and parameters. Without question, memory plays an extremely key role in the AI process.
On Chip or Off Chip?
Bandwidth, access time, energy consumption, capacity, and performance – all are affected if memory is on-chip or if it’s off-chip and far away from the AI processor. If it’s on chip, then the AI processor can interact with it and process the data extremely fast. But when memory is off chip, it takes two to six times more time to access the memory.
This poses the question as to which advanced memory is suitable for your AI applications. The two main contenders are high-bandwidth memory generation 2e (HBM2e) or graphics double-data rate 6 (GDDR6).
Each is highly rated and has its own set of design benefits for AI applications. But in this case, you have to be the judge because only you know the memory requirements for your next generation AI applications.
Here are the facts you should know about HBM2e and GDDR6, as shown in Fig. 1.
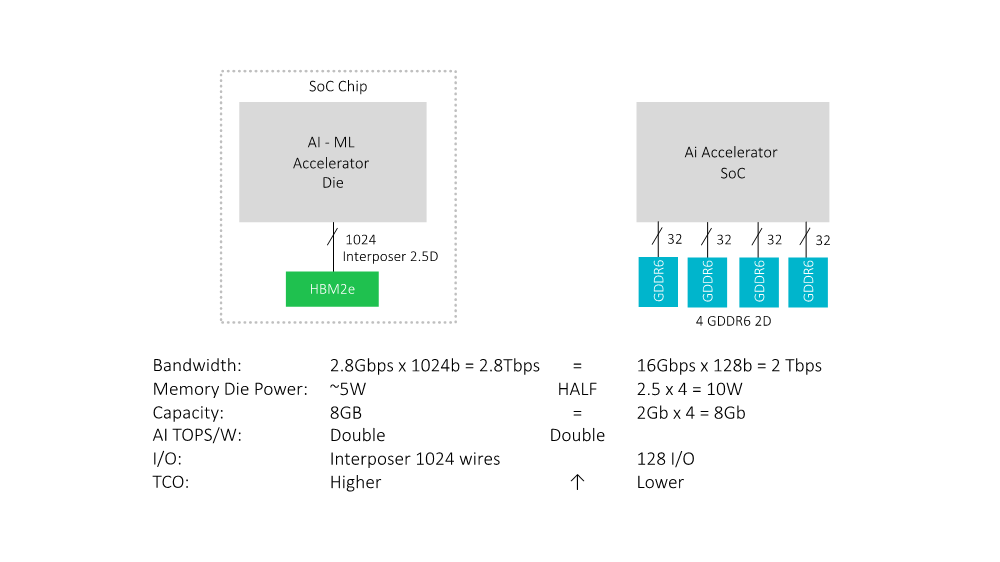
Listed in Fig. 1 are the top design considerations you should undertake when making your selection. Those are bandwidth, memory die power, capacity, AI tera operations per watt or TOPS/W, input/output (I/O), and total cost of ownership (TCO).
Certainly, to achieve TOPS/W performance for different AI architectures and systems, you could use different sizes, capacities, and levels of expected performance. However, in our example here, we’ll compare the same bandwidth requirement for a given AI accelerator design.
A one-device, one-stack HBM2e is used in this comparison. This has 8 Gigabits (Gb) of capacity, and bandwidth provides up to 2.8 terabits per second (Tb/s). As shown, in Fig. 1, under HBM2e, bandwidth is factored as 2.8 Tb/s times 1024 I/O equals the 2.8 Tb/s.
As for GDDR6, to achieve 2.0 Tb/s bandwidth, you require four devices. Each is up to 2 Gb capacity. Total capacity is the same as HBM2e’s 8 Gb. In the case of bandwidth, each GDDR I/O is about 16 Gb/s of bandwidth. So, 32 times 4 or 128 I/O of those four devices together gives you about 2 Tb/s. The point is a single device HBM2e can give you more bandwidth compared to the four GDDR6 devices.
Now, let’s check out power consumption. For HBM2e, it’s about five watts at 2.8 Gb/s bandwidth. Compared to GDDR6, for each of the four devices, it is about 2.5W for a total power consumption of 10W. It is clearly evident that a single HBM2e device is almost half that for a GDDR6 solution.
HBM2e Uses 2.5D Technology
Now, let’s go into system performance. AI chips are often compared in terms of tera floating-point operations per watt (TFLOPS/W). It’s important to point out that system designers and architects will build deep learning accelerators in different ways.
As shown in Fig. 2, HBM2e uses 2.5D packaging technology. It takes the die-to-die approach and is connected by a silicon interposer to an SoC or ASIC. As a result, it consumes less energy in a given operation compared to GDDR6. TOPS/W provided are clearly double in comparison to GDDR6.
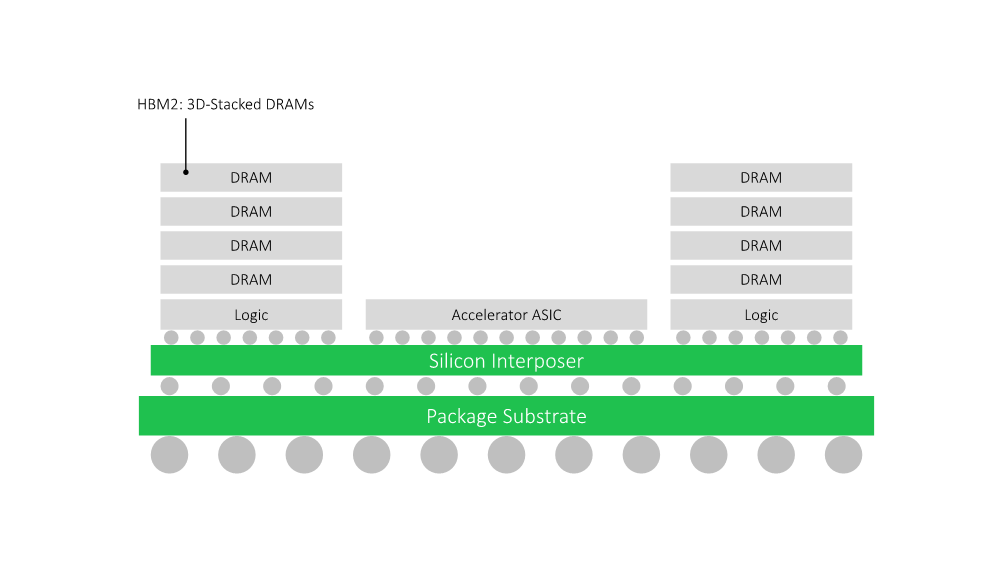
Therefore, HBM2e is more effective and provides you double the performance per watt compared to GDDR6 in such AI applications as video and image recognition. That’s because the processing element is directly connected to the HBM2e through the interposer across the dies. Therefore, floating point operations per watt offer much better performance. In contrast, in the case of GDDR6, functionality goes from one chip to the other. Thus, energy consumption and latency are much higher.
HBM2e Interposer and TCO
As mentioned above, HBM2e is a 2.5dB-based technology. That means an interposer is required when connecting an ASIC to the HBM2e memory. However, this interposer is an older 65nm process technology, hence it is less expensive. Since 2.5D packaging is a relatively new technology, the total cost of ownership (TCO) for HBM2e is slightly higher compared to GDDR6.
On the other hand, GDDR6 is a special, yet commodity memory. It’s available from three semiconductor vendors, whereas HBM2e is available from only two vendors today.
HBM2e, Wide I/O, and Low Power
Input/outputs (I/Os) are perhaps the biggest advantage HBM2e has over GDDR6. In the case of GDDR6, they are standard, high-speed single-ended I/Os. The SoC requires an additional 128 bit I/O for data, which is toggling at very high power and is also associated at risk command on the other signals, such as ground and power signals.
The interposer-based HBM2e, however, has a wide I/O going from die to die at a lower power consumption. So, memory controller PHY power consumption on the die is much less, compared to the typical GDDR6 PHY on a controller SoC.
Conclusion
When you factor in all the important design considerations in your new AI designs, it is worth your time to take a close look at HBM2e. It offers the same or higher bandwidth than GDDR6 and similar capacity. Power is almost half, and TOPS/W are doubled. Plus, HBM2e is a well proven solution in the industry.
There are other design considerations for both HBM2e and GDDR6 at the board level. Once you place these devices on the PCB, signal integrity, characterization, and board space issues emerge, as well as associated design considerations. In particular, special PCB manufacturing is required for interposer-based HBM2e and its 2.5D packaging.
–Sanjay Charagulla, Vice President, WW Business Development, IP Cores/Crypto, Rambus, Inc.

Subscribe to Newsletter

Test Qr code text s ss
