AI model recognises handwritten Chinese characters
Article By : Fujitsu
When benchmarked against a database of handwritten Chinese released in 2010 the technology achieved recognition accuracy of 96.3%.
Recognising individual handwritten Chinese characters using deep learning and other AI models may have already surpassed human recognition capability, but these models are still unable to correctly break strings of handwritten characters into individual characters.
Fujitsu is addressing this issue with a new AI model that it said has a high degree of accuracy in recognising handwritten Chinese character strings. By applying this model, recognition mistakes in characters have been reduced to less than half that of previous technology, greatly improving the efficiency of tasks such as digitisation of handwritten texts, according to the company.
The model will be used as part of Fujitsu's human centric AI Zinrai.
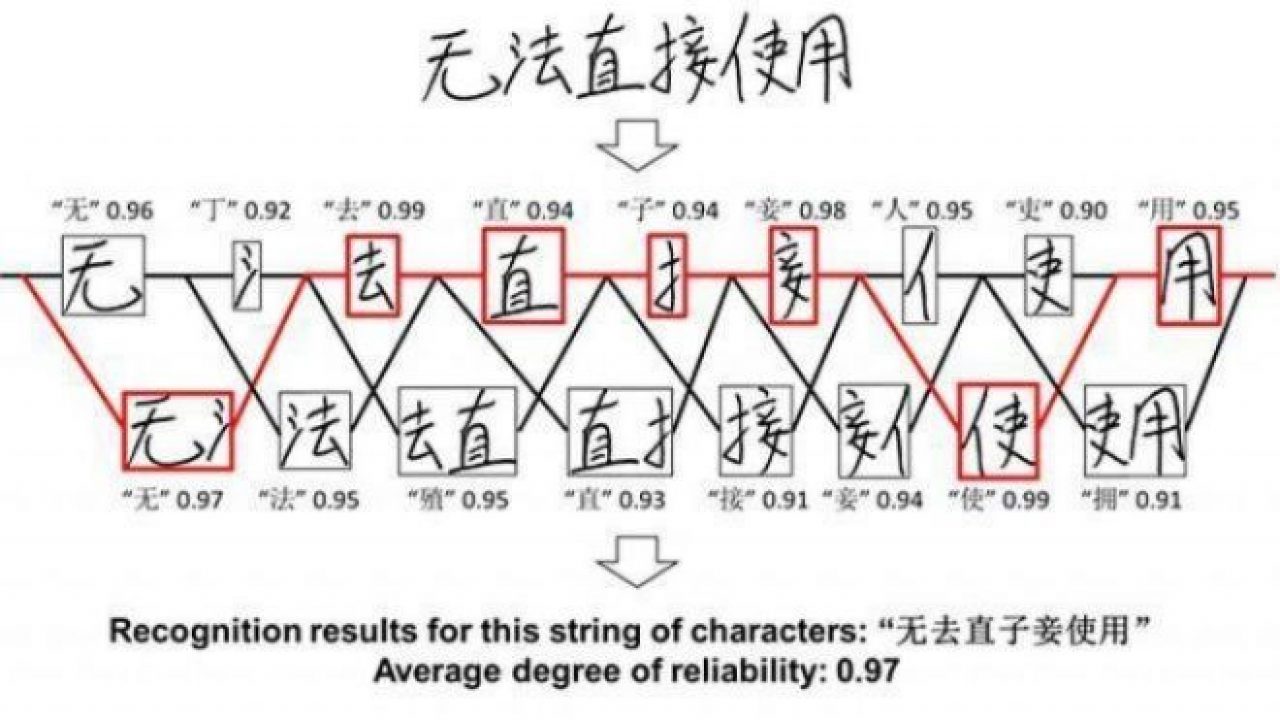
Existing technologies using AI start off with a supervised sample of characters to enable the system to learn and remember features of multiple character patterns used by humans when recognising characters. Next, an image of a string of characters would be divided into parts, and by determining the blank spaces would separate the radicals (the components that make up a Chinese character) and have situations where the separated areas would display a single region (top row of Figure 1), and situations when parts from neighbouring characters become a region (bottom row of Figure 1).
The program then assumes each region represents an individual character, and outputs the candidate character recognition result and its degree of reliability, using a recognition algorithm based on its earlier learning. The closer the degree of reliability is to one, the higher the program's reliability is of the candidate character. It finally outputs its recognition results by selecting in order the combination that has the highest average degree of reliability (bottom of Figure 1). With the previous technology, however, there were times when the system would output a high degree of reliability for images that were not characters, such as the component radicals, creating an issue where the system could not correctly separate characters.
![[Fujitsu AI Chinese 01 (cr)]](/wp-content/uploads/sites/2/2020/04/Fujitsu_AI_Chinese_01_cr.jpg)
__Figure 1:__ *Recognition results for a string of characters with existing deep learning models. (Source: Fujitsu)*
The Fujitsu-developed technology generates a high level of reliability only for proper characters. It does this by using a heterogeneous deep learning model, which, in addition to supervised character samples used in conventional technology, uses a newly developed supervised sample of non-characters made up of radicals, and combinations of parts which do not make up characters.
In a heterogeneous deep learning model, two types of supervised samples are used: one for existing characters, and another for non-characters. Compared with the supervised character sample, the supervised non-character sample achieved a huge number by dividing up characters and recombining them. Therefore, by having the system remember the features of non-characters that can easily appear in combinations of neighbouring parts in Chinese sentences, Fujitsu developed technology that can effectively learn, even with an asymmetrical deep learning model (Figure 2a).
![[Fujitsu AI Chinese 02 (cr)]](/wp-content/uploads/sites/2/2020/04/Fujitsu_AI_Chinese_02_cr.jpg)
__Figure 2:__ *Training and recognition processing with the heterogeneous structure deep learning model. (Source: Fujitsu)*
By inputting images of candidate areas into the trained heterogeneous deep learning model, and creating a system that outputs a degree of reliability for both characters and non-characters, high for candidate areas which form characters and low for candidate areas which do not, Fujitsu developed a technology that effectively separates a string of characters into individual characters. An existing Chinese language processing model is then applied, and based on an analysis of whether the recognition candidates form a string of correct Chinese, the final candidate sentence is output. Because the level of reliability for combinations of parts which do not form existing characters is lower than the level of reliability toward actual characters, by applying this recognition technology, correct recognition results can be achieved by selecting the segment path with the highest degree of reliability, beginning with the start of the string of characters.
When this technology was benchmarked against a database of handwritten Chinese released in 2010 by the Institute of Automation, Chinese Academy of Sciences (CASIA), which is used as a standard by academic societies, it achieved recognition accuracy of 96.3%, the highest achieved to date, surpassing previous technologies by 5%.
This technology is effective for languages that have no spacing between words, including Chinese, Japanese, and Korean. Fujitsu will aim to bring this technology to Zinrai in 2017, and apply it in stages toward a handwritten digital ledger system for Japan and other solutions.

Subscribe to Newsletter

Test Qr code text s ss
