AI Inferencing Chip Targets Edge Applications
Article By : Dylan McGrath
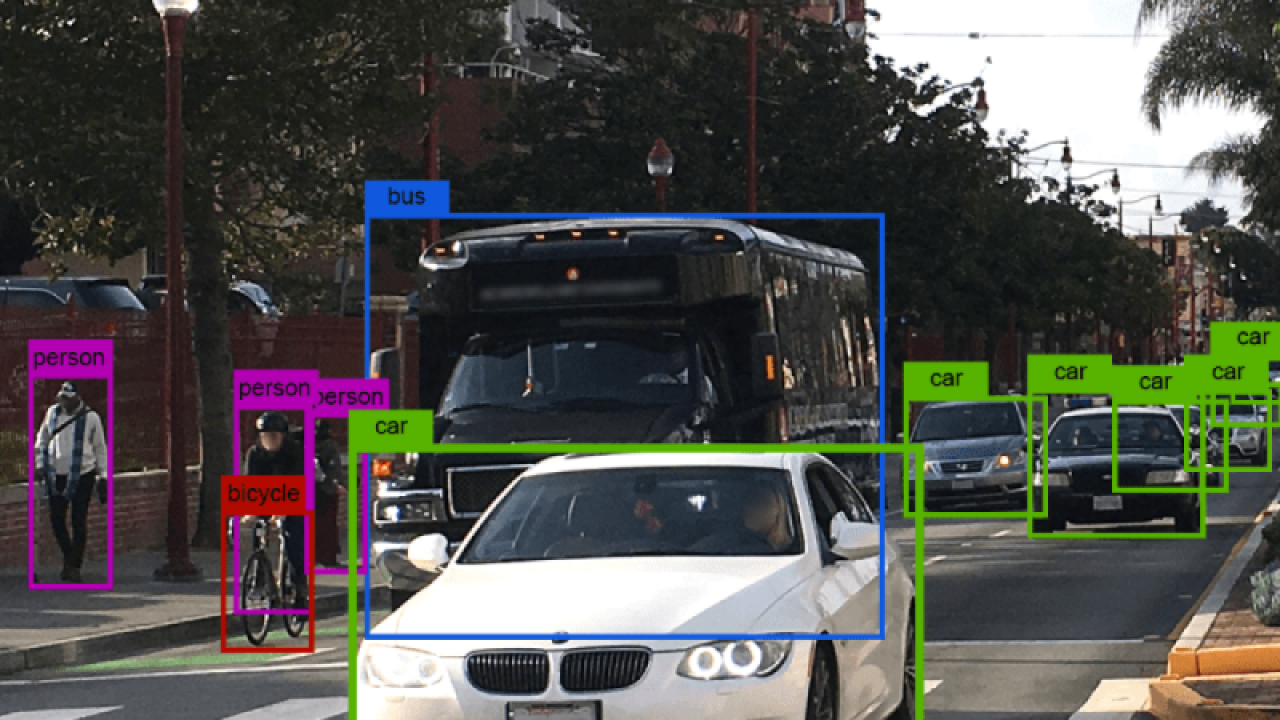
Flex Logix - best known as a supplier of embedded FPGAs and other IP - is marketing its first chip, an edge inference co-processor targeting edge applications
The Flex Logix InferX X1 chip is especially well-suited for gateways and low-end edge servers, which don’t require the raw performance of high-end data center chips but could utilize more throughput for AI inferencing, according to the company. The chip boasts performance on small batch sizes that is close to that of data center inference chips and offers high throughput in edge applications with just a single DRAM, keeping both system power and costs down, according to the company.
Based largely on the low DRAM bandwidth, the InferX X1 offers four times the throughput per watt and three times the throughput per dollar as Nvidia’s Tesla T4, the gold standard for higher-end data center servers, said Geoff Tate, Flex Logix CEO.
According to Tate, the InferX dramatically outperforms existing edge inference chips such as Intel’s Myriad X and Nvidia’s Jetson Nano on inferencing benchmarks such as YoloV2, YoloV3, and GoogleNet. The device’s performance advantage is especially strong at the low batch sizes required in edge applications in which there is typically only one camera or sensor, he said.
Tate said that the market for AI in edge servers is somewhat limited by the lack of chips available with the necessary performance at an appropriate sticker price. Customers are telling Flex Logix that a chip like InferX is exactly what they are looking for, he said.
“With a lower-priced card that’s close in performance to the T4, they can put them into many more products than they are shipping today,” Tate said.
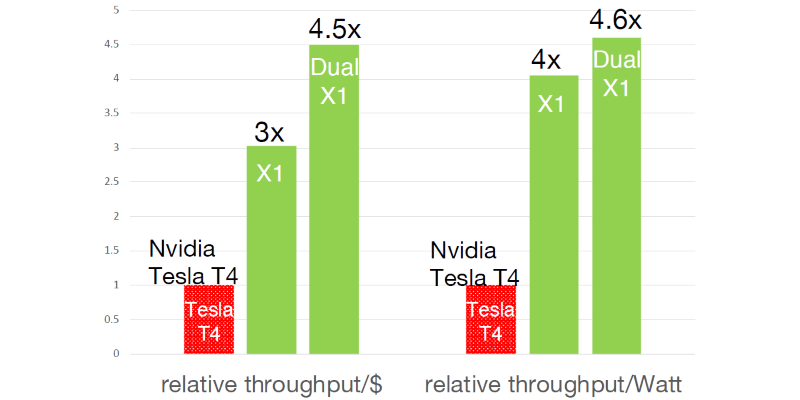
Flex Logix data showing its price/performance and performance/watt compared to Nvidia’s Tesla T4. (Source: Flex Logix)
Tate, who spoke with EE Times in advance of the chip’s unveiling at the Linley Processor Conference on Wednesday, emphasized that the InferX won’t have the throughput of the Tesla T4 but said that the device will ultimately sell for a fraction of the T4’s price, which is reportedly about $3,000. Tate declined to dictate the specific price of the InferX, saying that supply and demand factors would dictate the price of the device when it is available. The InferX is expected to tape out in the third quarter of this year and begin sampling by the end of the year.
Flex Logix, which continues to thrive in the eFPGA market, first entered the AI inference market last fall, announcing that it would license its nnMAX neural inferencing engine IP. The company claims that the engine can deliver more than 100 trillion operations per second (TOPS) of neural-inferencing capacity in a modular, scalable architecture that requires a fraction of the DRAM bandwidth of competing technologies. The IP is expected to be available for incorporation into SoCs by the end of the third quarter.

Subscribe to Newsletter

Test Qr code text s ss
