AI Gets Its Own System of Numbers
Article By : Sally Ward-Foxton

BF16, the new number format optimized for deep learning, promises power and compute savings with a minimal reduction in prediction accuracy
BF16, sometimes called BFloat16 or Brain Float 16, is a new number format optimised for AI/deep learning applications. Invented at Google Brain, it has gained wide adoption in AI accelerators from Google, Intel, Arm and many others.
The idea behind BF16 is to reduce the compute power and energy consumption needed to multiply tensors together by reducing the precision of the numbers. A tensor is a three-dimensional matrix of numbers; multiplication of tensors is the key mathematical operation required for AI calculations.
Most AI training today uses FP32, 32-bit floating point numbers. While this means the calculations are very accurate, it needs beefy hardware and uses a lot of power. Inference in general uses INT8, 8-bit integer (whole) numbers. While using lower precision number systems like INT8 offers more throughput on the same hardware, and therefore saves power, the results of the calculation (the prediction) are less accurate.
The idea behind BF16 is to optimize the tradeoff between precision and prediction accuracy in order to increase throughput.
Anatomy of an FP Number
Binary numbers in computing are represented as:
Mantissa x baseexponent where the base is 2.
In FP32, each number is represented by:
1 bit representing the sign (+ or -), followed by an 8-bit exponent, followed by a 23-bit mantissa (total 32 bits).
For BF16, Google Brain proposed reducing precision by truncating the mantissa of an FP32 number to 7 bits.
BF16 numbers are therefore represented by:
1 sign bit, then 8 exponent bits, then 7 mantissa bits (total 16 bits).
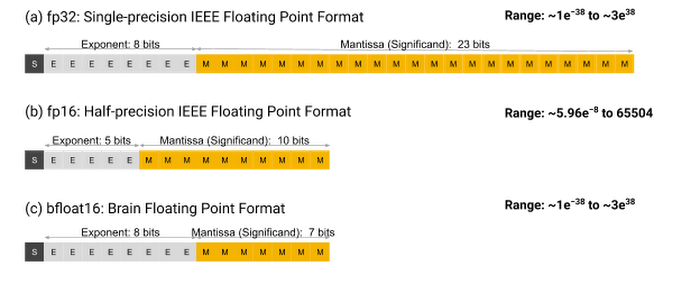
These 16-bit numbers offer the increased throughput that Google was after, while preserving the approximate dynamic range (the entire range of numbers that can be represented by this system) of FP32, since the exponent is the same size.
Prediction accuracy for algorithms using BF16 was similar, if not quite as accurate as FP32 (Google have said this is because neural networks are far more sensitive to the size of the exponent than the mantissa). For most applications, this is deemed to be an acceptable trade-off.
Why not use FP16?
The existing FP16 format, popular in mobile graphics applications, is also a 16-bit floating point number format. Why not just use that?
FP16 comprises:
1 sign bit, 5 exponent bits, then 10 mantissa bits (total 16 bits).
With this format, the exponent is smaller than for FP32, so the dynamic range is much reduced. Also, it’s much harder to convert FP32 numbers to FP16 than to BF16 – it’s a lot more work compared to just truncating the mantissa, which is a relatively simple operation.
Another important point is the physical area of silicon required for calculations. Since the physical size of a hardware multiplier increases with the square of the mantissa width, there are significant savings in silicon area gained by switching from FP32 to BF16 (enough to convince Google to use BF16 in its Tensor Processing Unit (TPU) chips). BF16 multipliers are eight times smaller than an FP32 multiplier, and still half the size of an FP16 equivalent.
What other formats are there for DL?
BF16 was not the only new number format proposed for deep learning. Nervana proposed a format called Flexpoint in 2017. The idea was to reduce computational and memory requirements by combining the advantages of point and floating point number systems.
Fixed point numbers use a fixed number of bits to represent an integer (whole number) and a fraction (the part after the decimal point) – in general it is simpler and faster to compute with fixed point numbers compared to the floating point formats described above. However, for a given number of bits, the dynamic range is much smaller for a fixed point number than a floating point number.

All the (floating point) numbers in a Flexpoint tensor used the same exponent (not just the same exponent size, the exact same exponent value). This exponent was shared between all the numbers in the tensor – so that communication of the exponent could be amortized across the entire tensor.
Multiplying tensors could then be done as a fixed point operation, since the exponent is the same for each calculation — this would be simpler than the maths required for floating point numbers. These calculations represent the vast majority of deep learning maths, so the savings would be significant. However, it was complex to manage the exponents, and the dynamic range (the range of numbers that could be represented) was low, because all numbers had the same exponent.
Flexpoint never took off and even Nervana’s own chips ended up using BF16 before their demise.

Subscribe to Newsletter

Test Qr code text s ss
