Is AI Robustness the Cost of Accuracy?
Article By : Junko Yoshida

Anyone poised to choose an AI model solely based on its accuracy might want to think again. A key issue, according to IBM Research, is how resistant the AI model is to adversarial attacks.
TOKYO — Anyone poised to choose an AI model solely based on its accuracy might want to think again. A key issue, according to IBM Research, is how resistant the AI model is to adversarial attacks.
IBM researchers, collaborating with other research institutes, are presenting two new papers on the vulnerability of AI. One study focuses on how to certify the robustness of AI against adversarial attacks. The other examines an efficient way to test resilience of AI models already deployed.
Of course, accuracy is the Holy Grail of AI. If computers can’t beat humans, why bother with AI? Indeed, AI’s ability to recognize images and classify them has vastly improved over the last several years. As demonstrated in the results of ImageNet competitions between 2010 and 2017, computer vision can already outperform human abilities. AI’s accuracy in classifying objects in a dataset jumped from 71.8% to 97.3% in just seven years.
Companies big and small have used ImageNet as a benchmark for their image classification algorithms against the dataset. Winning an ImageNet competition has bestowed bragging rights for AI algorithm superiority.
Robustness gap
However, the scientific community has begun paying attention to recent studies highlighting a robustness gap in well-trained deep neural networks versus adversarial examples.
Last summer, a team of researchers including IBM Research, the University of California at Davis, MIT, and JD AI Research published a paper entitled “Is Robustness the Cost of Accuracy? — A Comprehensive Study on the Robustness of 18 Deep Image Classification Models.”
According to Pin-Yu Chen, a research staff member in the AI Foundations at IBM’s Thomas J. Watson Research Center, the researchers cautioned, “Solely pursuing for a high-accuracy AI model may get us in trouble.” The team’s benchmark on 18 ImageNet models “revealed a tradeoff in accuracy and robustness.”
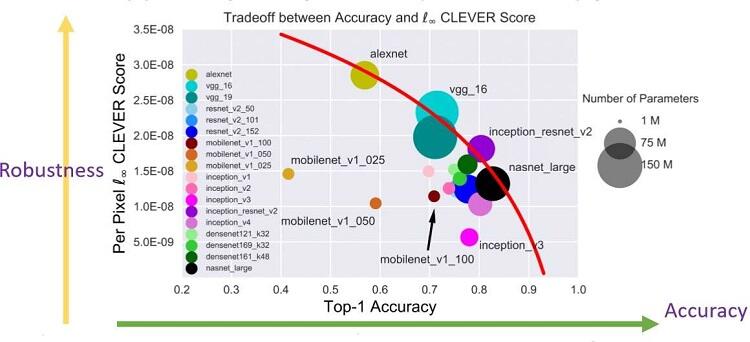
(Source: IBM Research)
Alarmed by the vulnerability of AI models, researchers at the MIT-IBM Watson AI Lab, including Chen, presented this week a new paper focused on the certification of AI robustness. “Just like a watch that comes with a water resistance number, we wanted to provide an effective method for certifying an attack resistance level of convolutional neural networks [CNNs],” noted Chen.
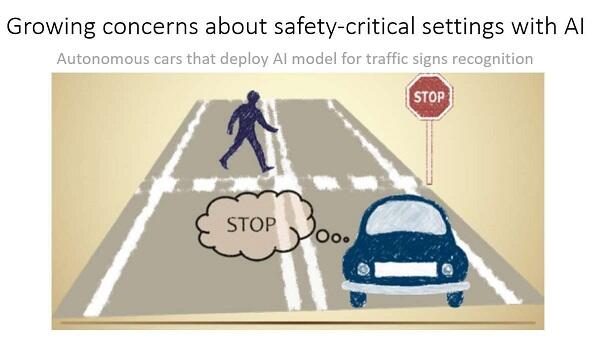
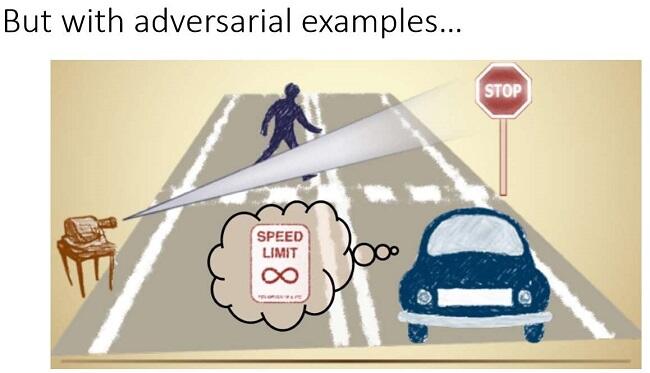
Why does this matter? It does because visually unnoticeable perturbations to natural images can mislead image classifiers toward misclassification. Chen said, “Think about safety-critical settings with AI.” An autonomous car that uses AI should readily recognize a stop sign. Yet when a minor optical illusion is cast on the sign from a nearby light source, the autonomous car sees the stop sign as a speed limit sign, Chen said. “The light source, in this case, has become a classic adversarial example.”
(Source: IBM Research)
(Source: IBM Research)
As a neural network is taught more images, it memorizes what it needs to classify. “But we don’t necessarily expect it to be robust,” said Chen. “The higher the accuracy is, the more fragile it could get.”
For autonomous vehicles, in which safety is paramount, verifying classification robustness is critical.
Techniques available today have been generally limited to certifying small-scale and simple neural-network models. In contrast, the joint IBM-MIT team found a way to certify robustness on the widely popular general CNNs.
The team’s proposed framework can “handle various architectures including convolutional layers, max-pooling layers, batch normalization layer, residual blocks, as well as general activation functions,” according to Chen. By allowing perturbation in each pixel with confined magnitude, said Chen, “We have created verification tools optimized for CNNs.” The team’s goal is “to assure you that adversarial attacks can’t alter AI’s prediction.”
Chen also pointed out that adversarial examples can come from anywhere. They exist in the physical world, digital space, and a variety of domains ranging from images and video to speech and data analysis. The newly developed certification framework can be applied in a variety of situations. In essence, it is designed to provide “attack-independent and model-agnostic” metrics, he explained.
The team also claims that its CNN certification framework is computationally efficient. It exploits the special structure of convolutional layers, reporting “more than 10× speed-up compared to state-of-the-art certification algorithms,” according to IBM Research.
Chen told us, “We’ve evaluated the input and output relations of each layer to create a matrix that is fast, certifiable, and general.”
Attacks on black-box neural networks?
Chen is also one of the authors of another paper focused on a much more efficient way to test for AI robustness, especially in “black-box” neural networks.
It’s not hard to imagine that someone with malicious intent — who’s very familiar with an AI model — finds the system’s weaknesses and exploits its vulnerability to create an attack. This falls into adversarial examples generated in a “white-box” setting.
But assume that you already have a self-trained AI/machine-learning system about to be deployed using a service provider. This might instill a false sense of security because very few actors have had access to the underlying AI model, let alone understand how it works. You’d assume that manipulating and attacking an AI model in a “black-box” setting would require too many time-consuming model queries, rendering the attack highly unlikely.
You’d be wrong in such an assumption, cautioned Chen. IBM Research and the University of Michigan recently developed a new method of testing AI systems — which could be already deployed — to determine their vulnerability to adversarial attacks.
Named AutoZOOM, or the Autoencoder-based Zeroth Order Optimization Method, the new method offers a “practical scenario” to attack AI models in a black-box setting, Chen explained.
As Chen explained, in a “white-box” world, an attacker can leverage knowledge of the AI model architecture and the model weights for inference to develop adversarial examples. In the black-box version, an attacker’s options are limited. An adversary can only access the input-output responses of the deployed AI model, just like regular users (e.g., upload an image and receive the prediction from an online image classification API). Hence, the attacker must resort to a brute-force approach, sending a huge amount of model queries to craft an adversarial example.
Using a previously developed method, Zeroth Order Optimization (ZOO), more than 1 million model queries were needed to find an adversarial bagel image, explained Chen. With the newly designed AutoZOOM framework, only tens of thousands of queries were necessary, he noted.

(Source: IBM Research)
Two new techniques used in AutoZOOM include 1) a way to “lessen the complexity of finding adversarial examples and reduce the number of queries to the black-box AI model” and 2) a technique that “guides the generation of adversarial examples using only a few model queries in each iteration of the attack process,” according to IBM Research. You can use “an autoencoder that is either trained offline with unlabeled data or a bi-linear resizing operation for acceleration.”
Chen called the AutoZOOM a practical way to test robustness in AI models. “You can apply this method to deployed AI systems to see if it is robust.”
Indeed, evaluating the robustness of AI will be necessary at a time when “machine learning as a service” is becoming more prevalent and widespread. Such a service is designed to make it easy for users to access powerful machine-learning tools for a variety of tasks.
Commercially available services include Google Cloud Vision API and Clarifai.com, designed to provide well-trained image classifiers to the public. Users can upload and obtain the class prediction results for images at hand at a low price. “However, the existing and emerging machine-learning platforms and their low model-access costs raise ever-increasing security concerns as they offer an ideal environment for testing malicious attempts,” the authors of the AutoZOOM paper cautioned. “Even worse, the risks can be amplified when these services are used to build derived products such that the inherent security vulnerability could be leveraged by attacks.”
As Dario Gil, vice president of AI and IBM Q at IBM Research, explained during his keynote speech at DAC last year, the horizon between narrow AI and broader AI (and, ultimately, general AI) is “still quite far away.” Several key AI research areas that still must be attacked include fairness, explainability, and lineage. AI’s robustness is the fourth pillar, said Chen.
The two papers offer a reminder that, with AI, training data can be noisy and biased. No one fully understands and can explain how neural nets learn to predict. Neural-network architecture can be redundant and lead to vulnerable spots. The black-box system can be powerful, but advocates can’t afford to turn a blind eye to its potential vulnerability to an adversarial attack.
Both papers mentioned above in this story were selected for oral presentation at the AAAI 2019 Conference on Artificial Intelligence taking place this week in Honolulu.
— Junko Yoshida, Global Co-Editor-In-Chief, AspenCore Media, Chief International Correspondent, EE Times.

Subscribe to Newsletter

Test Qr code text s ss
