Key Metrics for Evaluating an Inferencing Engine
Article By : Geoff Tate, CEO of Flex Logix

Advice on how to compare inferencing alternatives and the characteristics of an optimal inferencing engine.
In the last six months, we’ve seen an influx of specialized processors to handle neural inferencing in AI applications at the edge and in the data center. Customers have been racing to evaluate these neural inferencing options, only to find out that it’s extremely confusing and no one really knows how to measure them. Some vendors talk about TOPS and TOPS/Watt without specifying models, batch sizes or process/voltage/temperature conditions. Others use the ResNet-50 benchmark, which is a much simpler model than most people need so its value in evaluating inference options is questionable.
As a result, as we head into 2019, most companies don’t know how to compare inferencing alternatives. Many don’t even know what the characteristics of an optimal inferencing engine are. This article will address both those points.
1. MACs: how many do you need?
Neural network models involve primarily matrix multiplication with billions of multiply-accumulates. Thus, you need MACs (multiply-accumulators) and lots of them.
Unless you want to explore analog multiplication, you need to find an inferencing engine that does the kind of integer multiplication you feel is most appropriate for your needs for precision and throughput. For the bulk of customers today, the choice is integer 8×8 multiplication, with 16-bit activations for a 16×8 multiplication for some layers where this is critical for precision. Accumulations need to be done with 32-bit adders because of the size of the matrix multiplies.
For example, in an 8×8 multiplication, if you want 1 TeraOperations/second peak throughput capacity, you need 512 MACs running at 1 Gigahertz. One MAC is 2 operations: a multiply and an add. Thus, 512 x 2 x 1 Gigahertz = 1000 Billion Operations/Second = 1 TOPS (Tera-Operations/second).
This is just peak capacity and no architecture uses 100% of the available MAC operations, meaning you need to find an architecture that gets high MAC utilization for your model and your batch size.
If you want 1 TOPS of actual throughput you need 1 TOPS peak at 100% Utilization, 1.25 TOPS peak at 80% utilization, 2 TOPS peak at 50% utilization and 4 TOPS peak at 25% utilization.
Everyone needs MACs to do inferencing; the key is to minimize the number to get the throughput.
2. Weight loading must be fast, especially for small batch sizes
The main reason it is hard to keep MACs utilized is the huge number of weights involved. YOLOv3 has over 60 million weights that must be loaded in the MAC structure of every image. A high utilization architecture, especially for low batch sizes, must load weights quickly.
3. Memory: Keep it Local
Neural inferencing needs a lot of memory to hold images, intermediate results and weights.
DRAM memory accesses use significantly more power than on-chip SRAM accesses, while local SRAM accesses (1-2 mm distance from SRAM to MACs) uses significantly less than cross-chip SRAM accesses.
Mark Horowitz from Stanford presented this chart. The numbers are a few years old but the relative ratios remain relevant.
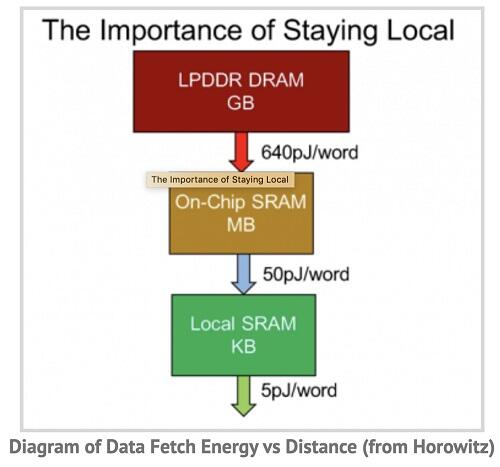
This chart shows that an optimal inferencing architecture will maximize the number of memory references that are local SRAM and minimize those that are from DRAM. Besides the power considerations, DRAM requires PHYs and a large number of BGA balls which drive up cost.
On-chip SRAM per byte is more expensive than DRAM, but the capacity of even the smallest DRAM is more than enough to hold the storage for YOLOv3 or other complex models. One DRAM is sufficient. When inferencing engines use four or eight DRAMs, they are buying them for bandwidth, not capacity.
4. Minimize Everything Else
MACs are a must-have in inferencing, hopefully with high utilization. You also must have sufficient on-chip SRAM to keep the MACs highly utilized, with perhaps 1 DRAM for storage of weights. In this scenario, an optimal inferencing engine should minimize everything else.
When you look at a pie chart of chip area, you want to see that most of the area is MACs and SRAM. When you look at a pie chart of chip power, you want to see that most of it is MACs and SRAM. If you see this, the inferencing engine is pretty close to optimal.
Conclusion
The four characteristics above are key to evaluating the real performance of a neural inferencing engine. You need high MAC utilization, low power and you need to keep everything small. It’s not rocket science, but without the availability of a standard set of benchmarks, customers are not quite sure what to look at when they start evaluating the myriad of inferencing engines that are coming on the market. AI processing, particularly at the edge, represents an enormous opportunity and the right inferencing engine will make or break your design.

Subscribe to Newsletter

Test Qr code text s ss
